구조체 : 내가 직접 만든 자료형 typeof struct _tagMyST { int a; // 변수 X, 구조체 멤버 float f; }MYST; int main() { MYST s = {}; // 변수 s.a; // 변수 안에 있는 내부 int 파트를 지칭하는 멤버 이름 MYST s2; MYST s3; s2.a; // 단순히 파트를 지칭하는 멤버 이름이기 때문에 여러 개가 있어도 각각 다름 s3.a; // 구조체 포인터 MYST* pST = &s; // 현재 구조체 MYST가 8 바이트 크기를 가지므로 아래처럼 동작시 8씩 계산하게 된다. pST + 1; // 구조체 포인터의 역참조 (*pST).a = 100; // 해당 a 파트에 100이 들어간다는 의미 (*pST).f = 3.14f; // 포인터..
메모리 영역은 다음과 같이 나눌 수 있다. 1. 스택 2. 데이터 3. 힙 4. ROM(읽기 전용 메모리, 코드 영역) 코드에 대해서 이야기하려면 문자 파트에 대해 알아보아야 한다. 문자 다음과 같이 char형 변수를 입력하고 디버깅을 해본다. c 메모리 안에 그냥 1이 아닌, 1 '\x1' 이 들어있음을 알 수 있다. // 문자 char c = 0; // char => 1 바이트 정수타입 자료형으로 문자를 입력하기 위한 전용 자료형이다. 이어서 char의 확장형이자 2 바이트 정수 타입으로 문자를 입력하기 위해 사용하는 wchar_t 자료형을 입력하고 디버깅해 본다. wchar_t wc = 49; wc에는 49가 아닌 49'1'이 들어가 있다. 두 자료형에서 ' ' 안에 들어 있는 것은 무엇을 의미할까..
반환할 것이 아무것도 없을 때 반환 타입으로 void를 쓴다.따라서 다른 자료형과 달리 void에서는 함수 종료 시 return을 해줄 필요가 없다. 이러한 void는 아래와 같이 포인터와 함께 사용되기도 한다.void* pVoid = nullptr; 포인터(*)앞에 붙는 자료형은 포인터 변수가 무언가를 가리킬 때 그 주소에 접근 할 때 사용할 자료의 단위를 말한다.이를 적용하면 void*의 경우 포인터가 붙었기 때문에 주소를 저장하는 포인터 변수는 맞지만,그 주소에 접근 할 때 원본의 형태를 어떻게 볼지를 정하지 않은 것이라고 할 수 있다. 원본의 형태를 정하지 않았기 때문에 아래의 예시처럼 어떤 변수의 주소든 다 받을 수 있다.// voidvoid* pVoid = nullptr;float* pFloa..
const// const int cint = 100; // 이 변수는 int 자료형으로 선언되었으나 const가 붙으며 상수화 되었다. // 상수화? => 값이 바뀔 수 없는 상태가 됨. // 이렇게 바뀔 수 없는 값을 r-value라고 한다. int ii = 10; // =를 기준으로 왼쪽에 있는 것이 변수, 오른쪽은 상수다. // 상수 = r-value, 바뀔 수 있는 값을 l-value라고 지칭함.cint = 100; // 상수인데도 int 변수를 잡았다는 것은 // 이것이 main 함수의 지역변수로서 존재하고 그 안에 1..
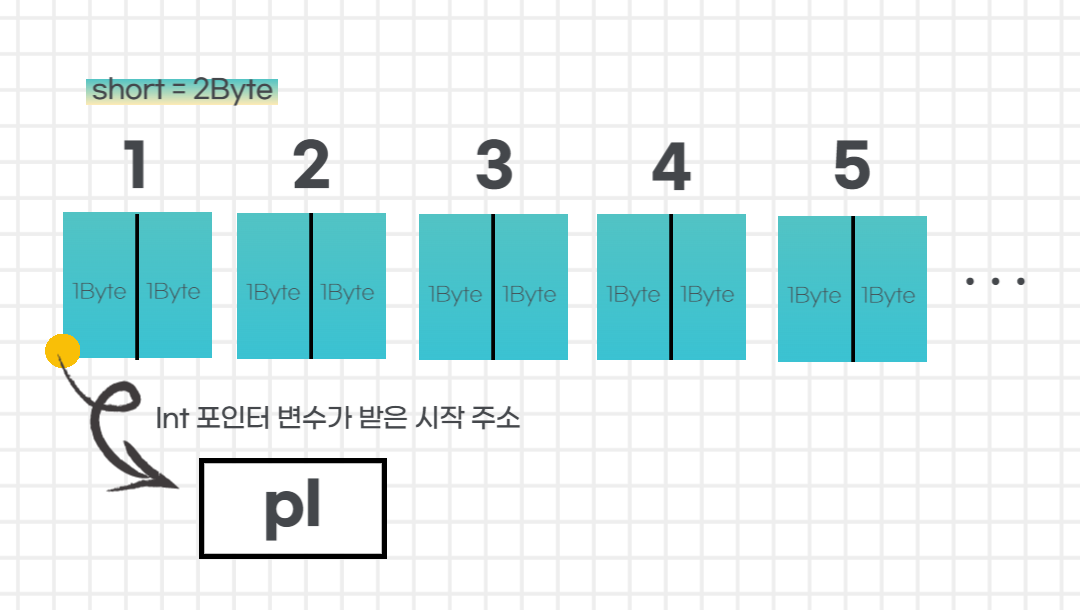
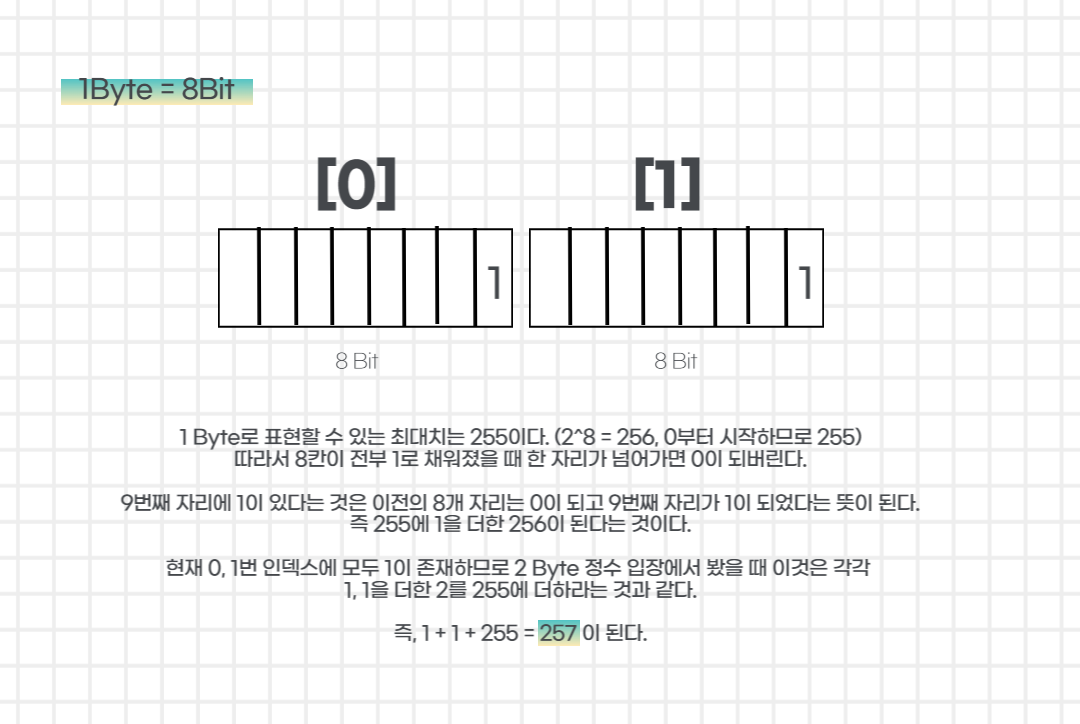
포인터 이해 확인 문제 풀이 1. 출력되는 값 iData의 값은 무엇이 될까?short sArr[10] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};int* pI = (int*)sArr;int iData = *((short*)(pI + 2));printf("1번 문제 정답 : %d\n", iData);먼저 short 타입은 2바이트 정수형이고, int 타입의 크기는 4바이트 정수형이라는 것을 생각해야 한다.첫 번째 줄 코드에 선언된 배열 내부는 이렇게 생겼을 것이다. 두 번째 줄의 다음 코드는 컴파일러 오류를 방지하기 위한 강제 캐스팅을 실행한다.int* pI = (int*)sArr;해당 코드를 실행하면 다음과 같이 int 포인터 변수 pI가 캐스팅에 의해short에서 int로 취급하는 ..
지난 시간에 배운 포인터 핵심 다시 되짚어보기#include #include int main(){ // 포인터 변수 // 자료형 변수명 int* pInt = nullptr; // 주소를 저장 char* pChar = nullptr; short* pShort = nullptr; // char* -> 주소를 따라가서 거기있는 데이터를 1byte짜리 정수형 자료로 해석함. // short* -> 주소를 따라가서 거기있는 데이터를 2byte짜리 정수형 자료로 해석함. // (실제로 어떤 값이 들어있는지는 포인터에게 중요치 않음. // 주소 안에 들어있는 값을 자료형이라고 생각하고 가져옴. // 따라서 정수 실수 구분이 잘못되면 제대로 작동하지..
컴퓨터와 메모리변수의 본질은 메모리이며, 모든 메모리는 자신의 위치를 식별하기 위한 근거로 고유번호를 가지는데, 이 번호를 메모리의 주소라고 한다. 이러한 메모리 주소는 보통 16진수로 표기한다.변수의 선언 및 정의는 메모리 확보를 의미하며 선언시 부여한 이름으로 확보한 메모리를 식별한다.변수를 이루는 세가지 요소1. 이름이 부여된 메모리2. 그 안에 담긴 정보3. 메모리의 주소단항 연산자인 주소 번지 연산자(=주소 연산자, &)를 사용하면 선택한 메모리의 주소를 가져올 수 있다.이를 %p 형식(주소 형식)으로 출력하면 16진수로 구성된 주소가 출력된다. 포인터 변수의 선언과 정의포인터 변수는 메모리의 주소를 저장하기 위한 전용 변수이다.모든 바이트 단위 메모리에는 고유번호(주소)가 붙어있다. 또한 이는..
visual studio의 내부 단위는 솔루션 -> 프로젝트파일(프로그램의 실체, 여러 개가 있을 수 있음) -> 그 외 서포팅을 위한 외부 라이브러리 등이 있다. 또한 디버그, 릴리즈 모드가 나눠져있으며 솔루션 플랫폼이 32비트(x86)용, 64비트 용이 존재한다. 지금은 64비트를 사용하는 것이 대중적이지만 32비트 기반 운영체제에서도 사용 가능하도록 비주얼 스튜디오가 빌드 기능을 지원하고 있다.대부분의 게임도 최저 사양으로 윈도우 64비트를 요구한다. 이는 게임의 사양이 높아졌기 때문이다. x86, x64는 OS의 데이터 처리 단위를 말한다. 그것이 작아지면 높은 사양의 게임을 실행할 때 메모리 문제가 발생한다. 따라서 32비트 운영체제에서는 PC 성능이 아무리 좋아도 높은 사양의 게임을 정상 실행..
typeof struct _tagMyST
{
int a; // 변수 X, 구조체 멤버
float f;
}MYST;
int main()
{
MYST s = {}; // 변수
s.a; // 변수 안에 있는 내부 int 파트를 지칭하는 멤버 이름
MYST s2;
MYST s3;
s2.a; // 단순히 파트를 지칭하는 멤버 이름이기 때문에 여러 개가 있어도 각각 다름
s3.a;
// 구조체 포인터
MYST* pST = &s;
// 현재 구조체 MYST가 8 바이트 크기를 가지므로 아래처럼 동작시 8씩 계산하게 된다.
pST + 1;
// 구조체 포인터의 역참조
(*pST).a = 100; // 해당 a 파트에 100이 들어간다는 의미
(*pST).f = 3.14f;
// 포인터를 역참조 할때 위처럼 (*pST)로 역참조하지 않고 아래의 방법으로 간략화할 수 있다.
pST->a;
pST->f;
return 0;
}
다음과 같이 char형 변수를 입력하고 디버깅을 해본다. c 메모리 안에 그냥 1이 아닌, 1 '\x1' 이 들어있음을 알 수 있다.
// 문자
char c = 0; // char => 1 바이트 정수타입 자료형으로 문자를 입력하기 위한 전용 자료형이다.
이어서 char의 확장형이자 2 바이트 정수 타입으로 문자를 입력하기 위해 사용하는 wchar_t 자료형을 입력하고 디버깅해 본다.
wchar_t wc = 49;
wc에는 49가 아닌 49'1'이 들어가 있다.
두 자료형에서 ' ' 안에 들어 있는 것은 무엇을 의미할까? 그것은 바로 아스키 코드(ASCII)라는 것이다.
이것은 미국 국제 표준 협회에서 지정한 각 문자에 대응하는 숫자를 맵핑시켜 놓은 표를 의미한다.
이에 따르면 숫자 49를 문자로 표현하면 '1'이 된다. 영문 대문자 A는 '65', 소문자 a는 '97'이다.
실제로 wchar_t wc에 65를 할당하고 디버깅해 보면 내부에 65'A'가, 97을 할당하면 내부에 97'a'가 들어 있음을 알 수 있다.
이를 통해 알 수 있는 사실은 다음과 같다.
컴퓨터에서 문자라는 개념은 '문자 이미지 표를 메모리에 저장해 두고, 특정 숫자가 보이면 그 숫자에 매칭되는 표에 있는 문자를 보여주는 것'이다. 즉, 우리가 한글이나 영어로 글자를 치더라도 메모리 상으로는 그 글자를 대응하는 숫자 데이터로 저장한다는 것이다.
즉, 아래처럼 메모리 상의 숫자 1과 문자로서의 '1'은 서로 다른 것이다.
char c = 1; // 1'\x1'
c = '1'; // 49'1'
이처럼 문자로서의 숫자들은 숫자가 아닌 문자로 봐야 한다.
이런 문자들이 나열되어 있는 것을 '문자열'이라고 한다.
wchar_t wc = 97;
wc = 459;
"459"; // 문자열에는 " " 을 사용한다.
2 바이트 정수의 459라고 한다면 내부 메모리에는 이 숫자를 표현하기 위한 2진수 숫자가 0,1,0,1, .... 형태로 들어있다.
그러나 문자로서의 "459"는 4에 해당하는 문자(52), 5에 해당하는 문자(53), 9에 해당하는 문자(57)가 연달아 들어있다.
이때 메모리 한 칸은 각각 1 바이트를 가진다.
하지만 단순하게 문자만 나열해 버리면 문자의 끝이 어디인지 알 수 없으므로, 현재 필요한 3번째 메모리 이후에도 문자가 있을 것이라고 착각할 수 있다.
따라서 각 문자열에서 어디가 끝인지를 알 수 있어야 한다. 이 역할을 하는 것이 0이다.
문자열 끝에 0이 있으면 해당 위치가 문자열의 마지막임을 알고 그 이전 메모리까지의 문자를 해석해 문자 "459"를 적는다.
+) 0에 대응하는 문자도 있지 않을까?
있다. 그것을 NULL문자라고 한다. 메모리 안에 정수 0이 들어있으면 그것을 문자로는 NULL 문자로 본다.
다만 주의할 것은 이것이 공백 문자와는 전혀 다르다는 점이다.
공백(Space)은 아무것도 없는 것이 아니라 메모리상에 32에 해당하는 1 바이트 정수가 들어있게 된다.
즉, "4 59"라고 적혀있다면 이것은 아래의 그림처럼 메모리상으로 [52], [32], [53], [57], [0]가 들어있는 것이다.
문자열 char(1byte), wchar(2byte)
8비트로 표현 가능한 수의 범위는 0~255이지만 UTF-8의 경우 맨 앞 한 자리를 앞 뒤 글자가 몇 바이트인지 나타내기 위해 앞에 1을 써야 하기 때문에 1칸이 줄어든 2^7 = 128로 0~127의 범위를 가지게 된다.
따라서 아스키코드도 127까지 존재하게 된다.
즉 1 바이트로 문자를 표현하면 127까지 표현할 수 있다.
반면 문자 하나를 2 바이트로 표현한다면 대응될 수 있는 값이 2^16 = 65536으로 약 6만 개이며, 이를 절반으로 나눠도 3만이 된다. 표현할 수 있는 문자의 수가 훨씬 더 많아지는 것이다.
문자에 대한 표현 방법은 아래와 같다.
// 문자
char c = 'a'; // 1 바이트 문자
wchar_t wc = L'a'; // 2 바이트 문자
// 문자열
char szChar[10] = "abcdef"; // 1 바이트 문자열
wchar_t szWChar[10] = L"abcdef"; // 2 바이트 문자열
// 마지막에 오는 Null문자열까지 합하여 총 7만큼의 크기를 가짐
// 따라서 szWChar[6] 이라고 선언하는 경우 오류가 발생함
// 문자열의 이런 초기화법은 문자에 해당하는 경우에만 허용됨
// 똑같은 2 바이트 정수 자료형이라도 short에서는 이와 같이
// 초기화 할 수 없음. 문자 자체는 대응 하는 숫자로 저장되기 때문
short arrShort[10] = { 97, 98, 99, 100, 101, 102, }; // szWChar에서의 방식대로 똑같이 short에서
// 초기화 하려고 하면 내부 저장 방식은
// 이처럼 숫자로 저장되는 것과 동일함
szWChar와 arrShort의 내부를 확인해 보면 아래와 같음을 알 수 있다.
따라서 배열 초기화 시 직접 " " 안에 넣어서 하는 경우는 문자에서만 가능하다.
이어서 다음의 코드를 살펴보자. 현재 pChar는 wchar_t 타입의 const 포인터로 선언되어 있는데, 2 바이트 크기의 문자열을 할당했는데도 VS 상에서 아무런 문법적 오류가 발견되지 않고 있다.
const wchar_t* pChar = L"abcdef";
이를 통해 문자열의 정체가 바로 주소값임을 알 수 있다.
문자열의 일반 배열과 포인터 배열의 차이
wchar_t szChar[10] = "abcdef"; // 포인터가 아닌 배열 상태. 존재하는 문자열을
// 저장하기 위해 20바이트 (2바이트 10칸)를 준비하고
// 메모리안 데이터를 하나하나 배열로 옮기겠다는 의미이다.
// 즉, 복사 붙여넣기
const wchar_t* pChar = L"abcdef"; // 2바이트 정수 문자에 정확하게 접근하기 위해 2바이트 포인터로 맞춤
// 위의 경우처럼 복사 붙여넣기가 아니라 다이렉트로 문자를 가리킴
아래위의 코드 모두 L자가 붙어있다. 이는 이 문자 데이터들을 한 칸 당 2 바이트씩 사용하겠다는 의미이다.
따라서 2바이트 자료형 포인터를 사용해야 이 주소를 맵핑할 수 있다.
자세히 설명하자면, 주소 변수에 어딘가의 주소를 받으면그 주소로 갔을 때 문자들이 있는 것이다. (한 칸 당 2 바이트씩 차지) 이때 컴파일러는 실제 데이터 타입이므로 주소 타입이 일치하지 않으면 일반적으로 오류를 낸다. 따라서 문자들의 데이터 타입이 w_char 타입이고 2 바이트 문자이기 때문에 그것에 맞춰 2 바이트 자료형 포인터를 사용하였다.
다음의 예시를 통해 더욱 확실하게 이해할 수 있다.
szWChar[1] = 'z';
위의 코드는 무엇을 의미할까? char 타입 배열 안에는 지역 스택 메모리 쪽으로 초기화한 값을 복사시켜 두었다. 그렇기 때문에 이 경우는 배열의 2번째 칸(0부터 시작하므로)에 있는 'b'를 'z'로 변경하라는 의미이다. 이번엔 아래의 코드를 보자.
// pChar[1] = 'z';
위의 코드는 무엇을 의미할까? 사실 이 코드는 잘못된 코드이다. 하지만 코드 자체만 봤을 때는 다음과 같이 해석할 수 있다.
전제 1. wchat_t 타입의 포인터는 배열로 구성된 문자열의 주소를 가리키고 있다. 전제 2. pChar[1]은 *(pChar + 1) = 'z'와 같다. 결론. 즉 'b'를 바꾸려는 것이 아니라, 주소 변수가 다이렉트로 입력된 주소로 접근해 pChar에서 + 1된 주소가 가리키는 것을 b에서 z로 바꾸겠다는 의미이다.
이 말은 아래와 같은 케이스라고 할 수 있다.
10 = 11;
10에 11을 할당하는 것은 불가능하다. 10이라는 것은 코드 그 자체인데, 그것에 11을 넣겠다는 것은 이치에 어긋난다.
마찬가지로, 문자열이라는 것은 어딘가에 있는 데이터를 읽어오는 것이 아니라 내가 작성한, 코드 자체에 적혀있는 구문이다. 따라서
wchar_t szChar[10] = "abcdef";
이 배열의 초기화 구문이 가진 의미는 실제 우리 프로그램이 실행될 때 기준으로 스택 메모리에 wchar_t 타입 10개만큼의 메모리가 잡힐 것이고, 거기에 내가 여기 작성해 놓은 이 문자 데이터를 그 공간에 복사시키라는 의미이다.
이때 아래의 *(pChar + 1) = 'z' 명령어는 다음과 같이 받아들여진다.
'우리 메인 함수 스택에 포인터 변수가 하나 있고, abcdf라고 작성해 놓은 코드 자체가 메모리 어딘가에 존재한다. 거기에 있는 문자 코드의 시작 주소를 이 포인터에 연결하라'는 의미이다.
코드는 우리 프로그램이 실행시켜야 할 어떤 명령어와 같다. 그 명령어 자체도 메모리상에 존재하고 있어야 한다. 그래야 명령어를 읽어 들이며 cpu가 그 명령어를 수행하며 거기에 적힌 대로 동작하기 때문이다.
하지만 명령어 안에 코드 자체에 필요한 데이터가 있기 때문에 그것을 가리키게 만든 것이다.
거기로 접근해서 그곳을 'z'로 수정한다는 것은 실시간으로 프로그램 실행 도중에 코드를 수정하는 것과 마찬가지이다.
여기서 중요한 사실을 한 가지 알 수 있다.
메모리 영역 중 ROM에 저장되는 코드는 읽기 전용(Read-Only) 메모리로 실행 중에 절대로 바뀌어서는 안 된다.
그래서 선언부를 다시 살펴보면 아래와 같이 pChar가 변경될 수 없도록 const 포인터로 선언되어 있다.
const wchar_t* pChar = L"abcdef";
const가 수식하고 있는 것이 wchar_t*이므로 원본 자체가 상수가 되었음을 알 수 있다.
지난 시간에 포인터를 배우면서 짚었던 것처럼 강제 캐스팅을 가하면 단순히 컴파일러 상에서는 문법 오류가 없기 때문에 변경이 가능하긴 하지만, 실행을 하면 코드 영역을 변경하려는 시도 때문에 프로그램이 터지는 문제가 발생한다.
멀티바이트 앞서 살펴본 내용에 의하면 문자열에 L자를 붙이지 않을 경우 1 바이트 단위 문자열이 되고 L자가 있는 경우 와이드 바이트라고 하여 모든 문자를 전부 다 2 바이트로 표현하겠다고 선언한 것과 같다고 하였다.
하지만 1 바이트로 표현하는 방식은 엄밀히 말하면 1 바이트로 표현하는 것이 아니다. Multi Byte Character Set이라고 하는 개념이 존재하기 때문이다.
이것은 문자에 따라서 가변 길이로 대응을 하는 것으로, 특정 문자들을 1 바이트로 표현하고 나머지 2 바이트로 표현하는 문자는 2 바이트로 표현한다. 따라서 L자가 붙지 않았을 경우 모든 문자를 1 바이트로 표현한다는 표현은 엄밀히 말하자면 잘못되었다. 멀티바이트에 의해 중간에 2 바이트 문자가 포함될 수 있기 때문이다.
코드로 예를 들면 다음과 같다.
char szTest[10] = "abc한글";
abc 다음에 한글이 들어오는 형태의 문자열이다. 한글의 경우 매칭되는 인덱스의 숫자가 매우 크다. 따라서 2 바이트로 표현해야 하는데, abc의 경우는 각각의 문자를 1 바이트로 표현할 수 있다.
하지만 멀티바이트 시스템은 이제 쓰이지 않고 있다.
마이크로소프트 윈도우에서만 이전에 개발된 시스템을 위해 어쩔 수 없이 남겨두었고, 현재 표준으로 쓰이고 있는 UTF-8이라는 문자 인코딩 방식과의 호환성 때문에 2 바이트 방식으로 넘어갔다가 또 인코딩을 해줘야 하는 문제들이 있다.
즉, 멀티바이트 시스템은 일반적으로 사용되지 않고 있으며 모든 문자를 2 바이트로 표현하는 와이드 바이트 시스템인 유니코드 문자 셋을 사용하는 것이 다른 부분들과의 호환성을 고려했을 때 훨씬 유리하다.
wchar_t szTestW[10] = L"abc한글"; // 유니코드 와이드 바이트 방식
VS 속성 페이지에서도 문자 집합의 디폴드 값이 유니코드 문자 집합 사용임을 확인 할 수 있다.
그렇다면 왜 멀티바이트는 이제 사용되지 않고 있을까?
멀티바이트의 문제점 문자가 나열되어 있을 때 메모리 상에 어떤 문자는 1 바이트고, 어떤 문자는 2 바이트일 수 있기 때문에 문자열에 문자의 수가 총 몇 개인지를 체크하고 싶을 때 기준이 모호 해진다.
그렇다면 문자열 안에 문자가 몇 개 있는지 아는 방법은 뭐가 있을까? 아래와 같이 wchar.h 헤더를 Include 한 뒤 문자열의 길이를 알려주는 기능을 가진 wcslen() 함수를 사용하면 된다.
이때 첫 번째 인자는 복사해 올 문자열로서 이를 수정 가능한 상태로 만들어야 문자열을 이어 붙이기 할 수 있으므로 const 없이 일반 wchar_t 포인터를 사용한다. 반면 문자열을 이어 붙일 때는 포인터로 원본 값을 훼손하지 않도록 const 포인터를 사용해 주었다.
이 함수에는 원형이 여러 개 존재하는데, 이를 설명하기 위해서는 함수 오버로딩에 대해 숙지 해야 한다. 관련해서 아래의 (※) 항목을 참고하면 된다.
※ 함수 오버로딩 함수명이 동일하더라도 인자의 개수가 달라지면 컴파일러가 둘 중 어떤 함수를 호출해야할지 판단할 수 있으므로 중복된 이름의 함수 선언이 가능해진다. 또는 인자 개수가 같더라도 인자 값의 타입이 다르다면 선언이 가능하다. (인자가 하나씩 있는 함수가 두 개있는데, 각각 int와 float을 인자로 삼는다면 서로 타입이 다르므로 선언 가능) 이러한 성질을 함수의 오버로딩이라고 부른다. 추후 클래스에서 함수 재정의를 뜻하는 오버 라이딩과 헷갈릴 수 있는 개념이므로 잘 숙지해야 한다.
다시 본론으로 돌아가서, 문자를 이어붙이는 작업을 수행하기 위해서는 넉넉한 메모리 공간이 필요하다.
우선 아래와 같이 변수를 할당하고 값을 넣어 결과를 확인해 본다.
wchar_t szString[100] = L"abc";
wcscat_s(szString, 100, L"def"); // szString은 이어붙여질 대상(원본),
// 100은 이어붙이려 하는 원본 공간의 사이즈,
// L"def"는 이어붙일 문자를 의미한다.
실행 결과 : 성공
직접 함수 작성해보기 추후 템플릿에 대해 배우면 더 좋은 함수를 작성할 수 있지만, 우선은 지금까지 배운 지식을 활용해 작성해본다. 실행 결과 정상적으로 결과가 출력됨을 알 수 있다.
#include <assert.h> // 디버깅 모드에서 오류가 생기면 경고를 발생시킨다
void StrCat(wchar_t* _pDest, unsigned int _iBufferSize, const wchar_t* _pSrc)
// (이어붙여지기 되는 원본, 원본 공간 사이즈, 붙이기 할 문자)
// 배열의 최대 개수를 받아가는 이유는 배열의 문자 공간이 이미 어느정도 차있을 때 뒤이어서 붙이려면
// 원래 지정된 공간을 초과해 버릴 수 있기 때문에 이를 방지하기 위해서이다.
{
// 작업을 시작하기 전에 문제가 있을지 없을지 부터 체크해 본다.
// 먼저 첫번째 원본 문자를 공간의 길이와 소스 문자의 길이 + 1(Null문자(0) 포함)를 합쳐
// 이것이 버퍼 사이즈를 초과하는지 여부를 체크한다.
// 이전에 우리가 만들어둔 GetLength() 함수를 사용해 해당 기능을 가져온다. (모듈화)
int iDestLen = GetLength(_pDest);
int iSrcLen = GetLength(_pSrc);
// 예외처리
// 이어붙인 최종 문자열 길이가 원본 저장 공간을 넘어서는 경우
if(_iBufferSize < iDestLen + iSrcLen + 1;) // Null문자 공간까지 계산(+1)
{
assert(nullptr); // 버퍼 사이즈보다 나머지 값들의 크기 총합이 크면 경고 처리+프로그램 종료
}
// 문자열 이어 붙이기
// 1. Dest (원본) 문자열의 끝을 확인(문자열이 이어 붙을 시작 위치)
// iDestLen; // Dest 문자열의 끝 인덱스
// 2. 반복적으로 Src 문자열을 Dest 끝 위치에 복사하기
/ 3. Src문자열의 끝 (Null 문자)를 만나면 반복 종료
// 횟수를 알고 있으므로 for문으로 처리
for(int i = 0; i < iSrcLen + 1; ++i) // Null 문자까지 처리하기 위해 +1 해주었음
{
_pDest[iDestLen + i] = _pSrc[i];
}
}
int main()
{
wchar_t szString[10] = L"abc";
StrCat(szString, 10, L"def");
return 0;
}
두 문자열을 받아서 양쪽의 문자열을 비교 체크하는 함수(strcmp()) 작성해보기
<조건> 1. 만약 두 문자열이 완벽하게 일치한다면 iRet이 0으로 나옴
2. 만약 같지 않으면 아스키 기준 누가 먼저 앞서냐에 따라 -1, 1이 된다. (우측이 앞서면 1)
3. 두 문자열의 내용이 완벽하게 같은 경우 문자열 길이가 더 짧은 쪽이 앞선다. EX. "가나" 그리고 "가나디"가 있다면 "가나"가 앞선다.
<정답>
int StrCmp(const wchar_t* _left, const wchar_t* _right)
{
// 양쪽 문자열을 받아온다.
int leftLen = GetLength(_left);
int rightLen = GetLength(_right);
int iLoop = 0; // 반복용 루프 횟수
int iReturn = 0; // 최종 결과값
// 두 문자열 중 짧은 것을 기준으로 반복한다.
// 이때 반복을 돌 때까지 두 문자열의 내용이 같은 경우
// 더 짧은 쪽이 우위를 가져야 하므로 미리 return 값을 -1, 1로 정해준다.
// 만약 서로 동일하다면 처음에 초기화 해준 0이 그대로 리턴될 것이다.
if (leftLen < rightLen)
{
iLoop = leftLen;
iReturn = -1;
}
else if(leftLen > rightLen)
{
iLoop = rightLen;
iReturn = 1;
}
// 본격적으로 두 문자열의 내부를 서로 비교해본다.
for (int i = 0; i < iLoop; ++i)
{
if(_left[i] < _right) // 왼쪽이 더 앞서므로 -1을 리턴한다.
{
return -1;
}
else if(_left[i] > _right[i]) // 아닌 경우 오른쪽이 더 앞서므로 1을 리턴한다.
{
return 1;
}
}
return iReturn;
}
int main(
{
int iRet = StrCmp(L"abc", L"abc");
}
포인터(*)앞에 붙는 자료형은 포인터 변수가 무언가를 가리킬 때 그 주소에 접근 할 때 사용할 자료의 단위를 말한다.
이를 적용하면 void*의 경우 포인터가 붙었기 때문에 주소를 저장하는 포인터 변수는 맞지만,
그 주소에 접근 할 때 원본의 형태를 어떻게 볼지를 정하지 않은 것이라고 할 수 있다.
원본의 형태를 정하지 않았기 때문에 아래의 예시처럼 어떤 변수의 주소든 다 받을 수 있다.
// void
void* pVoid = nullptr;
float* pFloat = nullptr;
{
int a = 0; // 원래 int*여야 오류가 발생하지 않지만, 포인터가 void 타입이므로 성립한다.
float f = 0.f;
double d = 0;
long long ll = 0;
pVoid = &a;
pVoid = &f;
pVoid = &d;
pVoid = ≪
}
반면에 이 원본의 형태를 정하지 않는 특성 때문에 void 포인터에서는 다음과 같은 역참조가 불가능하다.
*pVoid; // void 포인터에서는 이와 같은 역참조가 불가능하다.
// 원본의 형태를 무엇으로 해석할지 정해지지 않았기 때문이다.
또한 원본 형태가 정해지지 않았기 때문에 주소 연산을 할 수 없다.
pVoid + 1; // 이런 주소 연산이 불가능하다.
// 메모리의 주소로 가더라도 몇 byte를 해석해야 할지 알 수 없기 때문이다.
void 포인터의 특징을 정리하면 다음과 같다.
자신이 가리키고 있는 곳을 어떤 자료형으로 해석할지 미리 정하지 않는다. 따라서 모든 데이터 타입의 주소를 다 저장할 수 있다. 대신 역참조와 주소 연산을 할 수 없다.
// <const>
const int cint = 100; // 이 변수는 int 자료형으로 선언되었으나 const가 붙으며 상수화 되었다.
// 상수화? => 값이 바뀔 수 없는 상태가 됨.
// 이렇게 바뀔 수 없는 값을 r-value라고 한다.
int ii = 10; // =를 기준으로 왼쪽에 있는 것이 변수, 오른쪽은 상수다.
// 상수 = r-value, 바뀔 수 있는 값을 l-value라고 지칭함.
cint = 100;
// 상수인데도 int 변수를 잡았다는 것은
// 이것이 main 함수의 지역변수로서 존재하고 그 안에 100을 넣었다는 뜻이 된다.
// 즉, main 함수 스택 안에 cint라는 공간이 있고 그 안에 100을 넣었다는 것이다.
// 대신 const를 사용했기 때문에 상수로 못을 박았다.
// 그렇기 때문에 논리적으로는 값을 수정할 수 있게 되어야 맞지만,
// 문법적으로 제한을 했기 때문에 const를 붙임으로서 상수로 취급하고,
// 앞으로 개발자가 그것을 수정하려고 하면 문법이 검사를 해서 막아주겠다는 의미이다.
// 문법적으로 안되는데 그걸 어떻게 바꾼다는 말일까?
// 이전에 배운 포인터가 해답이다.
// 주소만 알아낼 수 있으면 주소로 접근해서 값을 바꿔버릴 수 있다.
pInt = (int*)&cint;
*pInt = 300;
printf("cint 출력 : %d\n", cint);
// 컴파일러 최적화(레지스터를 사용한 연산, 상수면 최초 선언시 저장된 상수값을 저장했다 불러옴)
// 로 인해 값이 100으로 출력되지만, 실제 공간을 디버깅해보면 300이 들어있다.
// 컴파일러 최적화 작업을 막기 위해 아래와 같이 맨 처음의 변수 선언부를
// volatile 키워드를 대체 사용하면 300이 출력 된다.
// volatile const int cint = 100;
const 포인터
#include <stdlib.h>
#include <stdio.h>
int main()
{
// 1. const
const int i = 100;
// const와 포인터
int a = 0;
int* pInt = &a;
*pInt = 1;
pInt = nullptr;
return 0;
}
const와 포인터 변수가 묶였을 때는 두 가지 경우가 생긴다.
1. 포인터 변수가 가리키고 있는 곳을 바꿀 것인가/말 것인가?
2. 포인터 변수 본인이 const가 되어 상수 처리되면 처음 한번 누군가를 가리키고 나면 딴 대상으로 변경할 수 없게 된다.
-> 이 두 가지 경우는 const가 붙는 위치에 따라 달라진다.
1. const가 앞에 붙는 경우 (const 포인터)
// <const 포인터>
// const가 앞에 붙음으로서 포인터 변수가 가리키고 있는 원본 쪽을 상수로 만든다.
const int* pConstInt = &a;
// *pConstInt = 100;
// 포인터 변수 자체가 상수가 된 것이 아니기 때문에 아래처럼 지칭하고 있는 주소를 변경할 수 있다.
// 즉, 다른 변수 주소값을 넣을 수 있다.
int b = 0;
pConstInt = &b;
// 다만 자기가 현재 가리키고 있는 원본 쪽을 수정할 수는 없다. (*pConstInt = 100;)
2. const가 뒤에 붙는 경우 (포인터 const)
// 포인터 const
int* const pIntConst = &a;
// 포인터 자체가 상수가 된다.
// 따라서 현재 주소 값의 원본에 해당하는 a를 바꿀 수 있다.
*pIntConst = 400;
// pIntConst = &b;
// 대신 다른 변수의 주소를 받을 수는 없다. (pIntConst = &b;)
// 포인터 변수 자체가 상수화 되었기 때문에 처음에 한번 입력받은 a의 변수가 곧 pIntConst와 동일시 된다.
위의 두 가지 경우를 조합하면 두 가지 기능을 동시에 상수화 할 수 있다.
const int* const pConstIntConst = nullptr;
// 초기화 시 가리킨 대상만 가리킬 수 있고, 가리키는 원본을 수정 할 수 없다.
헷갈리는 const 포인터 정리하기
드물게 사용되는 const 문법
int counst* p = &a;
*p = 0;
const가 수식하는 것이 (*)이므로 이는 첫 번째 경우인 const 뒤에 int*가 붙는 것과 동일하게 취급된다.
즉, 가리키고 있는 원본이 상수가 된다는 뜻이다.
이처럼 const가 붙은 포인터의 경우 const의 뒤에 무엇이 오는지, const가 수식하는 대상에 맞춰 상수화 결과를 해석한다.
헷갈리기 쉬운 개념
int a = 0;
const int* pInt = &a;
// a = 100;
// Q. 이 상황에서 위의 a = 100; 은 옳은 코드인가 잘못된 코드인가?
// A. 원본을 상수화 했다는 말은 원본이 상수가 되었다는 뜻이 아니라,
// 이 포인터의 기능에서 자기가 가리키는 대상을 수정하는 것을 막는다는 뜻이다.
// 즉, &a를 아래처럼 100으로 변경하는 것은 불가능하지만 a의 값을 100이나 3000으로 바꾸는 것은 가능하다.
*pInt = 100; // 잘못된 접근
// 원본인 a가 상수가 되었다는 뜻이 아니기 때문에
// 아래처럼 const 포인터가 아닌 일반 포인터 변수로는 이것을 언제든 수정할 수 있다.
int* p = &a;
*p = 100;
const 포인터는 왜, 언제 쓰는가?
입력받아야 할 데이터가 너무 많거나, 너무 크거나, 게임 상에서 두 개 이상 존재해서는 안 되는 유일성이 필요한 경우
▶ 이 경우 일반 타입으로 선언해 버리면 그런 데이터가 이미 있는 상태에서 그것을 복사해서 쓰게 된다. 이렇게 복사된 데이터는 함수가 종료됨과 동시에 사라진다. 이런 과정은 데이터가 작은 경우에는 크게 문제가 되지 않겠지만, 데이터가 커진다면 생성 소멸을 반복하는 것이 매우 비효율적이며, 함수가 자주 호출될수록 퍼포먼스가 매우 떨어지게 된다.
이 방법을 사용하는 대신에 이미 생성된 것의 원본에 접근할 수 있는 주소를 포인터로 가져다 쓰는 것이 훨씬 효율적일 것이다. 다만 이 방법을 사용할 때 다음과 같은 문제가 발생할 수 있다.
포인터를 사용하면 원본 값이 훼손될 수 있다.
전달해 준 주소를 통해 해당 값을 읽어보기만 하려던 것인데 작업을 하다 보면 원본 값이 의도치 않게 훼손되어 버리는 상황이 발생할 수 있는 것이다.
따라서 함수를 설계할 때 이 함수를 사용하는 동안 원본이 훼손되는 일이 없을 것이라는 것을 명시하기 위해 다음과 같이 표기한다.
void Output(const int * pI) // const가 붙었기 때문에 이 포인터로는 원본을 수정할 수 없다.
{ // 즉, '원본 데이터를 읽어 들이기만 할게요, 수정할 의도는 없습니다.'란 뜻
int i = *pI; // (O)
// 포인터를 이용한 단순 접근은 가능하다.
*pI = 100; // (X)
// 하지만 현재 const가 int*를 수식하고 있기 때문에
// 현재 가리키고 있는 원본을 변경할 수는 없다.
}
위의 예는 약간 비약적인 상황이다. int는 4 바이트이고 주소도 x64 환경이므로 8 바이트인데 둘의 차이가 별로 없기 때문이다. 그럴 바에는 int 변수를 그냥 복사하는 것이 더 싸다. (4 바이트가 훨씬 작기 때문)
현재 짚고 넘어갈 부분은 이 데이터 타입이 int가 아닌 엄청 거대한 타입일 경우를 얘기하는 것임을 명심하자. (EX. 구조체)
const를 사용한다고 해서 반드시 값을 바꿀 수 없는 것은 아니다.
아래의 방법처럼 강제 캐스팅을 사용하면 값을 변환할 수 있기는 하다.
void Output(const int * pI)
{
int i = *pI;
int* pInt = (int*)pI;
*pInt = 1000; //*pInt에 1000이 저장된다.
}
따라서 const 포인터 라는 것은 원본 값을 절대 못 바꾼다는 것이 아니라
이 함수를 설계한 사람의 의도를 비춘 것이라고 할 수 있다. ("바꿀 생각이 없다")
그러니 "절대"라는 말은 없다.
물론 이렇게 변환하는 것을 컴파일러가 문법적인 오류라고 잡아주기는 한다.
심지어 C++에서는 안전하게 const를 떼버리는 const 캐스트라는 것도 존재한다.
const_cast
위의 방식을 사용하면 const 키워드가 붙은 포인터를 일반 포인터로 바꿔 주는 역할을 한다.
하지만 강제로 의도를 비추면서 강제 캐스팅을 사용해 int 포인터 형태로 원형을 바꾸는 것은 가능하다.
C++은 자유도가 높은 만큼 이런 위험이 있다는 점을 숙지하고 이해도를 높이도록 노력하자.
먼저 short 타입은 2바이트 정수형이고, char 타입은 1바이트 크기의 정수형이라는 것을 생각해야 한다.
첫 번째 줄 코드에 선언된 배열 내부는 이렇게 생겼을 것이다.
이 상태에서 두 번째줄 코드를 살펴보자.
short* pS = (short*)cArr;
본래 char 타입이었던 배열의 주소를 받아 short 포인터 변수로 받았다. 이때 오류를 방지하기 위해 강제 캐스팅으로 char 타입의 배열을 short 포인터로 변환하여 넣어 주었다.
이 때의 작동 모습을 내부적으로 표현하면 다음과 같다.
세 번째 코드를 보면 앞서 해결한 1번 문제와 달리 특별히 캐스팅을 거치지 않고
바로 포인트 주소로 접근 명령 했음을 알 수 있다.
iData = *pS;
하지만 short 포인터는 이전 코드에서 그 주소를 2바이트 정수인 short로 보도록 명령받은 상태이다.
그렇기 때문에 주소 안에 short가 있을 것이라고 생각하면서 해당 주소에 접근하게 된다.
따라서 내부 메모리 구조를 아래와 같이 2바이트 정수라고 봐야한다.
그림에서 설명한 대로 계산을 진행하면 최종 답은 257이 된다.
3. 아래의 코드에서 테스트 함수를 호출하면 출력 결과가 어떻게 될까?
#include <stdlib.h>
#include <stdio.h>
int Test(int a)
{
a = 500;
}
int main()
{
int a = 100;
Test(a);
printf("출력 : %d\n", a);
return 0;
}
결과는 100 이 된다. Test 함수에서의 a 스택은 메인 함수의 a와는 별개의 메모리에 저장되어 있는 서로 다른 객체이다. 따라서 a라는 변수를 500이라고 할당해도 그것은 메인 함수에 있는 a가 아니며 함수 스코프 안의 a는 스택 메모리 영역에 있으므로 함수 종료 시 없어진다. 이를 개선하려면 다음과 같이 주소로 접근해야 한다.
#include <stdlib.h>
#include <stdio.h>
void Test(int* a)
{
*a = 500;
}
int main()
{
int a = 100;
Test(a);
printf("출력 : %d\n", a);
return 0;
}
a의 주소에 접근하였기 때문에 출력 시 a의 값은 500으로 변환된다. 이처럼 실제 변경하고 싶은 원본 데이터의 주소를 알려주면 그쪽에서 주소를 통한 역참조가 가능해진다. 이를 통해 원본 데이터의 값을 변환할 수 있다.
4. 위와 같은 논리로 scanf를 다시 살펴보자. scanf는 작동 시 주소를 요구한다.
scanf_s("%d", &a);
scanf 안의 (&)는 이 변수의 주소를 준다는 것을 의미한다. 이렇게 주소를 줬으므로 전달받은 주소에 접근해 그곳을 수정해 줄 수 있다.
scanf은 콘솔 창의 어떤 데이터로 입력해 주면 입력한 데이터를 내가 지정해 준 변수한테 넣어주는 역할을 한다.
따라서 scanf 함수 쪽에서는 호출 시 입력된 값을 입력받고 싶은 변수의 주소를 알려주어야 함수 안에서 콘솔 창에 입력된 데이터를 알려준 주소에 접근하여 넣어준다.
#include <stdlib.h>
#include <stdio.h>
int main()
{
// 포인터 변수
// 자료형 변수명
int* pInt = nullptr;
// 주소를 저장
char* pChar = nullptr;
short* pShort = nullptr;
// char* -> 주소를 따라가서 거기있는 데이터를 1byte짜리 정수형 자료로 해석함.
// short* -> 주소를 따라가서 거기있는 데이터를 2byte짜리 정수형 자료로 해석함.
// (실제로 어떤 값이 들어있는지는 포인터에게 중요치 않음.
// 주소 안에 들어있는 값을 자료형이라고 생각하고 가져옴.
// 따라서 정수 실수 구분이 잘못되면 제대로 작동하지 않는 것.)
return 0;
}
포인터 변수 자체의 크기는 얼마일까? 포인터는 주소를 저장하는 변수이다. 이러한 특징을 생각해 보면 포인터 변수에 함께 선언된 자료형의 크기와 포인터 자체는 관계가 없음을 알 수 있다. 함께 선언된 자료형은 해당 주소에 넣어둔 것을 어떻게 볼 것인지를 정하는 것뿐, 포인터의 근본은 주소를 저장하는 것이기 때문이다.
이전 운영체제 챕터에서 Window에 2종류의 플랫폼이 있다고 배웠다. (32비트_ x86, 64비트_x64) 포인터 변수의 크기는 하나로 고정된 것이 아니라, 플랫폼에 따른 가변 크기를 가진다.
- 왜 그럴까? 이를 이해하기 위해서는 운영체제 플랫폼의 비트 수 의미하는 바를 알 필요가 있다.
32비트 환경에서는 데이터를 처리하는 단위가 4byte씩이며, 64비트에서는 8byte이다. 4바이트에서 표현할 수 있는 주소는 2^32 제곱이므로, 0에서 2^32 제곱 - 1까지이다. (-1이 붙는 이유는 0부터 시작하기 때문이다).
이 2의 32 제곱은 대략 42억쯤 된다. 결국 4Byte로 표현할 수 있는 것은 42억 번지정도이다. 이것이 어느 정도 메모리 공간인지를 생각해 보면 42억 / 1024 = 약 4Gb가 된다. 32비트 운영체제에 RAM을 4기가바이트 이상 꽂아도 의미가 없다는 것이 바로 이런 맥락에서 나온 말이다. 애초에 메모리 공간에서 주소로 표현될 수 있는 것이 4기가바이트 까지 밖에 안되기 때문에 더 큰 크기의 RAM이 있어도 본래의 성능을 내지 못하기 때문이다.
반면 64비트 환경에서는 표현 가능한 주소가 42억 * 42억개이다. 4기가바이트 RAM을 42억개 꽂을 정도의 주소 범위를 가지는 것이다. 이렇게 8바이트 처리 단위를 가진 64비트 환경에서는 포인터 변수의 크기가 그 최대치인 8바이트가 된다.
정리하면 다음과 같다.
Q. 포인터 변수의 크기가 몇이에요? A. 목적으로 하는 운영체제 플랫폼이 뭐인지에 따라서 달라진다. 32비트 운영체제에서의 포인트 변수는 4바이트 크기를 가지고, 64비트 운영체제에서의 포인트 변수는 8바이트 크기를 가진다. 코드로는 다음과 같이 확인할 수 있다.
int iSize = sizeof(int*);
// 실행 결과 x64 환경에서는 8이, x86 환경에서는 4가 출력된다.
Q. 포인터 변수는 정수형 표현 방식을 따른다. int* 포인트 변수 pInt에 100번지라는 주소 번지가 저장되어 있고 i라는 변수가 시작 주소가 100이라는 주소로 가정하면 i변수의 가장 끝 부분은 어디일까?
A. 104가 된다. int가 4byte 자료형이며 주소는 1byte단위로 존재하기 때문이다. 아래의 그림을 보면 쉽게 이해할 수 있다.
A. 정수 표현 체계를 따르므로 100에 1을 더했을 때 101이 되어야 한다. 하지만 실제로는 104가 된다. 표현 방식이 정수이긴 하지만, 포인터(주소)의 연산은 일반적인 정수의 연산 체계를 따르지 않는다.
포인터 입장에서 +1이란, 주소를 한 개 증가시키라는 의미이다. 여기서 하나를 증가하면 곧이곧대로 1을 더해서 101번지가 되는 것이 아니라, 다음 int가 있는 위치로 가겠다는 의미이다. 현재 int의 끝부분이 104이므로 만일 이 뒤에 새로운 int가 존재한다면 그것은 104번 주소에서부터 시작될 것이다. 따라서 기존 주소 100에서 int 포인터의 크기인 4씩 증가시킨 104가 된다.
Q. 그렇다면 char* 에게 +1을 하라고 한다면 값이 어떻게 변할까?
A. char 자료형은 1byte의 크기를 가지므로 주소값은 기존 100번지에서 1byte 크기를 더한 101이 된다.
Q. short* 에게 +1하면 값이 어떻게 변할까?
A. short 자료형은 2byte의 크기를 가지므로 주소값은 기존 100번지에서 2byte 크기를 더한 102가 된다.
위에서 살펴본 내용의 결론은 다음과 같다.
주소의 증감 단위는 자료형의 사이즈 단위로 움직인다.
예를 들어 pInt는 int* 변수 이기 때문에, 가리키는 곳을 int로 해석한다. 따라서 주소값을 1 증가하는 의미는 다음 int 위치로 접근하기 위해서 sizeof(int) 단위로 증가하게 된다.
배열을 제대로 설명하려면 포인터가 필요하다 -> 포인터와 배열의 상관관계 알아보기
// 포인터와 배열
// 배열의 특징
// 1. 메모리 공간이 연속적으로 이어진 구조이다.
// 2. 배열의 이름은 배열의 시작 주소이다.
// 따라서 아래의 iArray라는 배열의 이름이 곧 배열의 시작 주소이다.
int iArry[10] = {}; // int 10묶음을 한 번에 선언했다. {} 안이 비어있으므로 전체를 0으로 초기화한다.
// int 단위로 접근
*(iArry + 0) = 10; // 배열의 인덱스의 첫번째는 0으로 본다.
// 배열의 단위가 int이고 0을 더했으므로 배열의 첫 번째 칸에 10을 할당한다.
// [] <- 이 괄호 연산자는 *(iArry + 0)와 서로 동일한 의미이다.
*(iArry + 1) = 10; // 배열의 단위가 int이고 1을 더했으므로 (4byte) 배열의 2번째 칸에 10을 할당한다.
#include <stdio.h>
#include <string.h> // strlen() 함수를 사용하기 위한 헤더 포함
int main(void)
{
// 문자 배열 (char[16]의 선언 및 정의)
// 선언한 크기는 char[16]이지만 초기화는 char[6] 문자열로 한다.
char szBuffer[16] = { "Hello" };
// 문자 배열을 가리키는 문자 포인터 변수의 선언 및 정의
char *pszData = szBuffer;
int nLength = 0;
// pszData 포인터 변수가 가리키는 대상에 저장된 char형 데이터가
// 문자열의 끝을 의미하는 NULL 문자가 될 때까지 반복문 수행
while (*pszData != '\0')
{
// 포인터를 다음으로 한 칸 이동 시킨다!
pszData++;
nLength++;
}
// strlen() 함수로 문자열의 길이(바이트 단위 크기)를 출력한다.
printf("Length : %d\n", nLength);
printf("Length : %d\n", strlen(szBuffer));
printf("Length : %d\n", strlen("World"));
return 0;
}
while(*pzData != '\0')의 pszData가 가리키는 요소는 반복문을 한 번 수행할 때마다 계속 다음 글자가 저장된 요소의 주소로 변경된다. 'szBuffer'라는 배열의 이름은 상수이고 변하지 않는다. 따라서 이 변하지 않는 주소를 기준으로 상대주소를 계산하여 배열의 각 요소를 식별할 수 있다.
하지만 포인터는 변수이므로, 자신이 담고 있는 정보를 바꿔버리는 것 자체가 상대 주소 계산이 됨과 동시에 새로운 기준 주소로 변경된다.
즉, 계산을 통해 얻은 상대주소로 정보를 업데이트 하면 그것이 새로운 기준주소가 되어 인접한 정보에 접근할 수 있게 된다.
배열의 이름은 상수(r-value)이므로 이것을 기준 주소로 하여 상대 주소들을 계산해 각 배열 요소를 식별한다. 반면 포인터는 변수(l-value)에 해당하기 때문에 자신이 담고 있는 정보를 바꿀 수 있고, 이렇게 바뀐 정보 자체가 상대 주소 계산임과 동시에 이 상대 주소 정보가 업데이트 됨으로서 새로운 기준 주소가 되기 때문에 인접 정보에 접근할 수 있게 된다.
주소 차이를 이용해 문자열의 길이를 측정하는 예
#include <stdio.h>
int main(void)
{
char szBuffer[16] = { "Hello" };
char* pszData = szBuffer;
// 문자열의 길이를 측정하기 위해 NULL 문자가 저장된 위치를 찾아낸다.
while (*pszData != '\0')
{
pszData++;
}
// NULL 문자가 저장된 위치(주소)에서 시작 위치(주소)를 빼면
// 문자열의 길이를 알 수 있다.
printf("Length : %d\n", pszData - szBuffer);
return 0;
}
코드의 6번 라인에서 두 포인터 변수를 szBuffer로 초기화 했고, 이 주소는 'Hello'라는 문자열이 저장된 배열의 0번 요소의 주소이다. 결과적으로 첫 글자 'H'가 저장된 주소로 볼 수 있는데 이 주소가 문자열 전체를 식별하기 위한 기준주소가 된다.
예제 코드에서 pszData의 주소는 최초 기준주소(szBuffer)에서 계속해서 증가했다. 따라서 반복문을 실행한 후, pszData(상대주소)에 담긴 주소는 szBuffer(기준주소)보다 크거나 같아진다.
이 가정에 의해 14번 라인(예제의 마지막 printf 부분처럼) 연산하면 문자열의 끝인 '\0'이 저장된 배열 요소의 인덱스를 알 수가 있는데, 이 인덱스가 문자열의 길이와 일치하게 된다. 즉, pszData(상대주소) - szBuffer(기준주소)처럼 상대주소에서 기준주소를 빼서 역으로 인덱스를 계산할 수 있다.
문자열의 복사 - char *strcpy(char *strDestination, const char *strSource); 인자 : strDestination - 문자열이 복사되어 저장될 메모리의 주소 strSource - 원본 문자열이 저장된 메모리의 주소 반환값: strDestination - 인자로 주어진 주소 반환 설명 : 문자열의 길이를 계산하여 원본의 크기만큼 대상 메모리에 복사하는 함수
- char *strncpy(char *strDestination, const char *strSource, size_t count); 인자 : strDestination - 문자열이 복사되어 저장될 메모리의 주소 strSource - 원본 문자열이 저장된 메모리의 주소 count - 복사할 문자열의 길이 반환값 : strDestiniation - 인자로 주어진 주소반환 설명 : count 인수로 주어진 길이만큼 대상 메모리에 문자열을 복사하는 함수
strncpy() 함수는 memcpy() 함수처럼 길이를 명시하지만 (길이 = count), 이는 memcpy() 처럼 바이트 단위 크기가 아니라 문자열의 길이를 명시하는 것이다
기능면에서 memcpy() 함수와 거의 흡사하게 두 메모리 내용을 복사하는 기능을 수행한다. 하지만 복사할 메모리의 크기를 기술해야 하는 memcpy() 함수와 달리 strcpy() 함수는 메모리의 내용이 모두 문자열이라고 한정하므로 복사 해야 할 메모리 크기를 스스로 결정한다. 따라서 굳이 복사할 메모리 크기를 기술할 필요가 없다.
이러한 strcpy() 함수는 '깊은 복사'문제 때문에 자주 사용된다. 그러나 함수 자체에 보안결함이 있으므로, 윈도우에서는 strcpy_s()를 사용하는 것이 좋다.
<깊은 복사와 얕은 복사>
- 깊은 복사(Deep Copy) : 두 주소가 가리키는 대상 메모리 전체의 내용을 복사함으로써 각각의 주소나 포인터가 독립된 대상을 가리키고 있지만, 그 안에 담긴 내용을 일치할 수 있도록 복사본을 만드는 행위를 뜻한다.
- 얕은 복사(Shallow Capy) : 대상이 아닌 포인터만 복사하는 행위를 뜻한다.
포인터를 다룰 때 대상이 둘이 되는 것을 바라는 것이 아닌, 단지 주소 정보만 따로 담아 관리하기를 원할 때가 있다. 이 경우 실제 대상이 둘이 되도록 하는 것은 의도와 다른 결과이므로 둘을 구별하여 코드를 작성하지 않으면 심각한 오류가 발생할 수 있다. 즉, 단순 대입 대신 strcpy() 함수를 이용해 두 메모리에 저장된 내용(문자열 등)을 깊은 복사하도록 해야 한다. strcpy() 함수 대신 memcpy() 함수를 사용해도 된다. 이후로는 return 이전에 반드시 메모리를 해제하는 코드를 함께 추가해야 메모리 누수 문제를 예방할 수 있다.
메모리 비교 - int memcmp(const void *buf1, const void *buf2, size_t(count); 인자 : 1. buf1 - 비교 원본 메모리 주소 2. buf2 - 비교 대상 메모리 주소 3. count - 비교할 메모리의 바이트 단위 크기 반환값 : 1. 결과가 0이면 두 값은 같다. 2. 결과가 0보다 크면 buf1이 buf2 보다 더 크다. 3. 결과가 0보다 작으면 buf2가 buf1보다 더 크다. * 단, 뺄셈 연산 수행 시 unsigned char 형식으로 처리하므로 -1은 255가 된다. 설명 : 첫번째 인자로 전달된 주소의 메모리에 저장된 값에서 두 번째 인자로 전달된 주소에 저장된 메모리의 값을 뺄셈 연산하여 두 값이 같은지 비교한다. 즉, 주어진 길이만큼 두 메모리를 비교하는 연산이다. 두 메모리에 저장된 정보를 일정 단위로 잘라서 감산 연산한 결과가 0인 동안 계속 반복한다.
memcmp() 함수의 사용방법은 mcmcpy() 함수와 유사하다. 그러나 memcpy() 함수의 기능이 일종의 단순 대입 연산자와 같다면 memcmp() 함수는 두 대상을 비교하여 같은지 다른지를 비교하는 기능을 제공한다. 즉, memcmp() 함수는 상등/부등 연산자(==, !=)와 같다.
이를 이용해 만약 값을 10번 비교한다면 10개항 모두 1:1로 비교 감산하며 결과가 전부 0일 때 두 대상이 같다고 결론짓는다. 도중에 하나라도 0이 아닌 경우(=값이 다른 경우) 같지 않다고 결론을 내린 뒤, 구체적으로 두 대상 중 어느쪽이 숫자가 더 큰지 작은지 확인하며 무엇이 다른지 알아낸다.
이 과정의 결과로 함수가 양수를 반환하면 첫번째 인수로 전달 된 주소의 메모리에 저장된 정보가 두 번째 인수로 전달된 메모리의 내용보다 더 큰 값이 된다. 반대로 음수가 전달되면 첫번째 주소의 메모리에 저장된 정보가 두번째 것보다 작다는 것을 의미한다.
- int strcmp(const char* string1, const char *string2); 인자 : 1. string1 : 비교할 문자열이 저장된 메모리 주소 2. string2 : 비교할 문자열이 저장된 메모리 주소 반환값 : 1. 두 문자열이 같다면 0 반환 2. 만일 0보다 큰 수를 반환하면 string1이 string2보다 알파벳 순서상 뒤이고, 0보다 작으면 string2가 뒤에 순서임을 의미 설명 : 대소문자를 식별해서 두 문자열이 같은지 비교하는 함수
strcmp() 함수는 memcmp() 함수와 매우 유사하다. 특히 뺄셈 연산으로 두 정보가 같은지 비교하는 원리가 동일하다. 그러나 비교 대상이 되는 정보를 메모리 주소가 아닌 '문자열'로 가정해서 처리하다 보니, 메모리의 길이를 매개변수로 받지 않는다.
따라서 비교 방법이 memcmp() 함수와 동일하지만, 문자열의 경우 길이가 다를 수도 있다. 길이가 다르면 일단 둘은 다른 문자열로 취급되는데, 어느 문자열의 값이 더 큰지 비교하는 방법은 사전에서 단어를 검색하는 방법과 완전히 일치한다. 예를 들어 문자열 "Test"가 "TestString"보다 사전상 더 앞서는 것과 같은 이치다.
덧붙여서 strcmp() 함수를 이용하면 문자열 앞에서 일정 길이만 비교할 수도 있다.
문자열 검색 char *strstr(const char *string, const char *strCharSet); 인자 : string - 검색 대상이 될 문자열이 저장된 메모리 주소 strCharSet - 검색할 문자열이 저장된 메모리 주소 반환값 : 1. 문자열을 찾으면 해당 문자열이 저장된 메모리 주소 반환 2. 문자열을 찾지 못하면 NULL 반환 설명 : 임의의 대상 문자열에서 특정 문자열을 검색하는 함수
strstr() 함수는 strcmp() 함수처럼 두 문자열의 주소를 인수로 받아 검색하여 결과를 반환하는 함수이다. 첫 번째 인수로는 검색 대상 문자열이 저장된 메모리 주소를, 두 번째 인수로는 검색할 문자열이 저장된 메모리의 주소를 받는다. 만일 찾지 못하면 NULL을 반환하며, 성공 시에는 검색 대상 메모리에 찾으려는 문자열이 저장된 메모리 주소를 반환한다.
배열 연산자 풀어쓰기 1차원 배열을 포인터 관점으로 보면 기준 주소에서 일정 인덱스만큼 떨어진 상대주소를 배열 요소의 변수로 저장하는 연산이다. 즉, *(기준 주소+인덱스)와 기준주소[인덱스]는 같은 뜻이 된다.
이처럼 배열을 간접지정 연산자로 풀어낼 수 있다면, 복잡한 이론들도 쉽게 이해할 수 있다.
#include <stdio.h>
#include <string.h>
int main(void)
{
char szBuffer[32] = { "You are a girl." };
// 배열의 첫 번째(0번) 요소의 값을 %c 형식으로 출력한다.
printf("%c\n", szBuffer[0]);
// 0번 요소에 대한 주소인 배열의 이름(주소)에 대해 간접지정 연산을
// 수행하고 그 안에 담긴 정보를 출력한다.
printf("%c\n", *szBuffer);
// 0을 더하더라도 주소는 달라지지 않는다.
printf("%c\n", (*szBuffer+0));
// 배열 연산자는 '기준주소 + 인덱스' 연산결과로 얻은 주소를
// 간접지정한 것과 같다.
printf("%c\n", szBuffer[5]);
printf("%c\n", *(szBuffer + 5));
// 주소연산(&)은 간접지정 연산과 상반된다.
// 그러므로 아래 세 줄의 코드는 모두 같다.
printf("%s\n", &szBuffer[4]);
printf("%s\n", &*(szBuffer + 4));
printf("%s\n", szBuffer + 4);
return 0;
}
위의 코드를 살펴보면 코드의 외형은 다르지만 사실상 내용이 완전히 일치하는 부분이 존재한다.
// 배열의 첫 번째(0번) 요소의 값을 %c 형식으로 출력한다.
printf("%c\n", szBuffer[0]);
// 0번 요소에 대한 주소인 배열의 이름(주소)에 대해 간접지정 연산을
// 수행하고 그 안에 담긴 정보를 출력한다.
printf("%c\n", *szBuffer);
// 0을 더하더라도 주소는 달라지지 않는다.
printf("%c\n", (*szBuffer+0));
*(szBuffer+0)은 szBuffer[0]을 풀어쓴 것이고, 0은 더하든 빼든 결과에 아무런 영향이 없는 값이므로 동일하게 szBuffer[0]이 된다. 또한 배열을 이루고 있는 요소의 자료형이 char 형이므로, 배열연산이나 간접 지정 연산의 결과는 모두 char 형 변수(l-value)가 된다. 따라서 %c 형식문자로 출력한다. 형식 문자 중 %s는 문자열에 대응되는데, printf() 함수는 %s와 대응된 인수를 메모리의 주소로 보고 그 인덱스를 기준으로 한글자씩 뒤로 넘어가 0이 나올 때까지 범위에 있는 문자들을 하나의 완성된 문자열로 출력한다.
realloc(), sprintf() 함수 - void *realloc(void *memblock, size_t size); 인자 : memblock - 기존에 동적 할당된 메모리 주소. 만약 이 주소가 NULL이면 malloc() 함수와 동일하게 동작한다. size - 다시 할당받을 메모리의 바이트 단위 크기 반환값 : 다시 할당된 메모리 덩어리 중 첫 번째 바이트의 메모리 주소. 만일 다시 할당하는데 실패하면 NULL 반환 이 경우 첫번째 인자로 전달된 메모리를 수동으로 해제 해야 함. 설명 : 이미 할당된 메모리 영역에서 크기를 조정할 수 있다면 반환된 주소는 첫 번째 인자로 전달될 주소와 같다. 그러나 그것이 불가능하다면 기존의 메모리를 해제하고 새로운 영역에 다시 할당한 뒤, 새로 할당된 메모리의 주소를 반환한다. EX. 4인 테이블에 이미 네 사람이 앉아 있는데, 다른 친구들이 더 오자 자리를 옆의 6인 테이블로 옮겨 앉는 것
너무 큰 크기의 메모리로 확장을 시도하는 경우 운영체제가 공간을 늘려주는 것이 아예 불가능 한 것처럼, 만약 realloc() 함수가 아예 실패하는 경우 함수는 NULL을 반환하며 첫번째 인수로 전달된 메모리를 해제해주지 않는다.
realloc() 함수가 제공하는 기능을 가능하게 하는 것은 동적 할당하는 메모리가 내부적으로는 일정 크기의 덩어리 (memcry chunk)로 관리되기 때문이다. 쉽게 말해 malloc()나 realloc()함수는 '메모리 공장'인 운영체제로부터 메모리를 큰 크기의 덩어리로 가져와 그것을 일정 크기로 잘게 자른 뒤 분배하는 메모리 소매상과 같은 역할을 한다.
- int sprintf(char *buffer, const char *format[, argument] ... ); - 인자 : buffer :출력 문자열에 저장될 메모리 주소 format : 형식 문자열에 저장된 메모리 주소 [, argument] 형식문자열에 대응하는 가변 인자들 - 반환값 : 출력된 문자열의 개수 - 설명 : 형식 문자열에 맞춰 특정 메모리에 문자열을 저장하는 함수, 문자열이 콘솔 화면에 출력되는 것이 아니라 특정 주소의 메모리에 출력된다.
sprintf() 함수는 strcpy() 함수와 유사하지만, 형식 문자열을 조합할 수 있다는 점에서 편리하다. 다만 strcpy() 함수와 sprint() 함수는 모두 보안 결함이 있으므로, strcpy_s()와 sprintf_s() 함수를 사용하는 것이 좋다.
잘못된 메모리의 접근 이전에 배열에서는 '\0' 문자를 이용해 끝을 알 수 있게 한다고 배웠다. 그러나 C/C++에서는 유효하지 않은 메모리에 대한 접근이 가능하기 때문에, 문법적으로 배열이거나 동적할당을 받았을 때는 메모리의 경계검사 문제를 늘 신경써야 한다. 아래의 예제는 동적할당 시 배열의 경계 문제를 보여준다.
// badpointer01.c
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
char* pszBuffer = NULL;
pszBuffer = (char*)malloc(12);
gets(pszBuffer);
puts(pszBuffer);
// 오류 확인을 위해 의도적으로 해제하지 않음
// free(pszBuffer);
return 0;
}
예제에서 12바이트의 메모리가 할당되었으므로 그 이상의 메모리를 사용하려 하면 동적 할당된 메모리 단편이 훼손된다. 문자열의 끝인 '\0'부분을 넘어서는 부분까지 입력했기 때문에 0을 메모리에 덮어쓰면서 경계를 넘기게 되고, 이 때문에 기존에 다른 변수의 값이 저장되어 있던 메모리 공간에 잘못 입력한 부분까지 덮어쓰게 되기 때문이다.
이런 메모리 훼손 사실은 할당된 메모리가 해제될 때 나타나는데, 이 예제에서는 메모리를 해제하지 않았기 때문에 경계를 넘긴 입출력을 수행하는 치명적인 오류가 발생했음에도 아무런 오류 메시지도 출력하지 않는다.
이렇듯 gets()함수를 사용하면 겉으로는 멀쩡하게 돌아가는 코드인 것 같아도 내부적으로는 문제가 발생하는 경우가 있을 수 있으니 gets_s() 함수를 사용하거나 fgets() 함수를 쓰는 것이 바람직하다.
이처럼 메모리의 경계를 넘긴 입출력을 수행하거나 자신에게 할당된 메모리가 아닌 전혀 엉뚱한 메모리에 대해 입출력하는 경우 문자열이 깨지는 오류가 발생한다. 이런 오류를 해결할 때는 코드를 눈으로 훑는 단순 디버깅에 그치지 않고 메모리를 그림으로 그려서 표현하고, 디버거를 사용해 모두 추적하는 방법으로 변화를 확인해야 한다.
포인터의 배열과 다중 포인터 포인터가 어려운 이유는 포인터 그 자체도 '변수(=메모리)'라는 사실 때문이다. 변수는 메모리이고, 그 메모리는 관리 목적의 고유번호(=주소)가 존재한다.
일반변수의 경우에는 이름과 주소 그리고 그 안에 저장된 정보로 총 3가지의 구성이 서로 명확하게 구별된다. 그러나 포인터의 경우 포인터 변수 자체로서의 주소와 포인터 변수 안에 저장된 주소까지 총 2개의 주소가 공존한다.
이런 관점에서 생각해보면 다중포인터라는 것은 사실 단순한 일반 포인터와 다를 것이 없다. 그저 포인터가 가리키는 것이 포인터 변수가 된 상황일 뿐이다.
int형 변수를 가리키는 포인터를 *int라고 표기하는 것처럼, int*에 대한 포인터는 int**로 기술된다. 이렇게 선언된 포인터 변수에 대한 간접지정 연산을 수행한 결과는 포인터의 대상 자료형에서 (*) 하나를 지운 것과 같다.
포인터 자료형
간접지정 연산결과 (가리키고 있는 것)
적용 코드 예
char *
*(char *) == char
int nData = 10; int *pnData = &nData;
char * *
*(char **) == char*
int* *ppnData = &pnData;
char** *
*(char ***) = char**
int** *pppnData = &ppnData;
다중 포인터를 배우기 전에 포인터도 변수라는 사실과 간접지정 연산 결과의 자료형이 무엇인지를 명확히 알 수 있어야 이해력을 높일 수 있다는 점을 알아두자.
char* 의 배열 다중 포인터가 등장하는 이유는 흔히 '포인터의 배열' 때문이다. 여기서 포인터 배열이란 배열의 요소가 포인터 변수인 경우이다.
char형 배열은 문자(배)열 일 수 있다. 그리고 늘 그렇듯 배열은 0번 요소의 주소로 식별된다. 따라서 배열을 식별하는 주소는 배열(char[5]을 이루고 있는 요소 자료형(char)에 대한 포인터 (char*)에 담는다. 그리고 &s 형식 문자는 자료형 char*에 대응해야 하며, %c는 char형에 대응 해야 한다.
#include <stdio.h>
int main(void)
{
// char* [3] 배열을 각각의 문자열로 초기화
char *astrList[3] = { "Hello", "World", "String" };
// 배열의 요소가 char* 이므로 %s로 출력하는 것이 맞다.
printf("%s\n", astrList[0]);
printf("%s\n", astrList[1]);
printf("%s\n", astrList[2]);
// 배열의 0번 요소에는 첫 글자가 저장된 메모리의 주소가 들어 있다.
// 여기에 정수를 더해 '상대 주소'를 계산한다.
printf("%s\n", astrList[0] + 1);
printf("%s\n", astrList[1] + 2);
printf("%s\n", astrList[2] + 3);
// char*의 배열의 논리적으로 char의 2차원 배열과 같다.
printf("%c\n", astrList[0][3]);
printf("%c\n", astrList[1][3]);
printf("%c\n", astrList[3][3]);
return 0;
}
포인터를 나타낼 때 사용하는 (*)는 포인터가 가리키는 대상을 따라가면 어떤 형식의 데이터가 나온다는 의미이다.
astrList를 char*의 배열 혹은 char**로 볼 수 있다. 따라서 asrtList에 대해 배열 연산을 한 번만 수행하면(간접지정 연산을 한 번만 수행하면) 결과적으로 *(char**)형식의 연산이 되고, 괄호 안과 밖에 있는 '*'를 하나씩 지우면 char*가 된다.
위 코드는 결국 char* + int 형식의 상대주소 계산 연산이며 연산결과의 자료형은 char*가 된다. 따라서 자료형이 char* 인 것은 맞지만 기준주소보다 오른쪽으로 인덱스만큼 이동한 상대주소로 부터 문자열을 출력하므로 더한 인덱스만큼 앞 글자들을 출력하지 못하게 된다.
위의 코드는 char** 간접지정 연산을 두 번 수행한 것과 같다. astrList[1][3]을 풀어쓰면 *(*(astrList + 1) + 3)이다. 최종 결과 자료형은 정수 인덱스를 더해도 변하지 않기 때문에 정수 부분을 빼면 *(*(char**))가 된다. 불필요한 괄호를 지워보면 **(char**)가 된다. 따라서 최종 결과 자료형은 char가 되며, 자료형이 char이기 때문에 %c로 출력해야 한다.
주소 연산과 간접지정연산은 서로 정반대되는 개념의 연산자이다. 만일 두 연산자가 괄호 안이나 밖에서 연속되는 경우에는 두 연산자가 상쇄되므로 무시할 수 있다.
예를 들어 char* astrList[3]이 선언되고 &astrList[1]이라는 연산이 수행되었다면 이 연산 결과의 자료형은 char**가 된다. '&astrList[1]' 이라는 연산이 수행되었다면 이 연산결과의 자료형은 char**가 된다.
'&astrList[1]'을 풀어서 쓰면 &*(astrList + 1)이다. 이 때 &*은 서로 상쇄된다. 즉, 그냥 astrList + 1이라고 한 것과 똑같다.
또한 astrList의 자료형은 char* [3] 혹은 char** 이므로 &astrList[1]의 자료형은 char**로 볼 수 있다.
다중 포인터 아래의 포인터에 대한 포인터 변수를 선언 및 정의한 다중 포인터 예제를 살펴보자.
#include <stdio.h>
int main(int argc, char* argv[])
{
char ch = 'A';
// char* 에는 char형의 주소를 담는다.
char* pData = &ch;
// char** 에는 char* 형의 주소를 담는다.
char** ppData = &pData;
// char*** 에는 char** 형의 주소를 담는다.
char** *pppData = &ppData;
// 아래 코드들은 모두 char 형식을 %c로 출력한다.
printf("%c\n", ch);
printf("%c\n", *pData);
printf("%c\n", **ppData);
printf("%c\n", ***pppData);
return 0;
}
이 예제의 핵심은 "포인터도 변수이고 모든 변수는 주소를 가졌다"이다. 포인터 변수 자체의 주소와 포인터 변수에 담긴 주소를 구별하여 연산할 수 있다면 몇 중 포인터인지는 중요하지 않다. 또한 **(char***)의 연산 결과 자료형이 char*임을 안다면 어려울 것이 없다.
포인터 변수를 선언할 때 'char*이름', 'char *이름', 'char * 이름' 가운데 어떤 식으로 선언해도 상관없다. 중간에 존재하는 공백은 문법적으로 아무런 의미가 없기 때문이다. 이 예제에서 굳이 공백으로 구분한 것은 무엇이 포인터이고 포인터가 가리키는 대상이 무엇인지를 코드 딴에서 명확히 구별하기 위함이다.
#include <stdio.h>
int main(int argc, char* argv[])
{
char* astrList[3] = { "Hello", "World", "String" };
// astrList의 요소 형식이 char* 이므로 char**에 담는다.
char* ppstrList = astrList;
// char** 형식 변수의 주소는 char***에 담는다.
char** pppstrList = &ppstrList;
// *(char** + 인덱스)의 형식은 char*이다.
// 따라서 %s로 출력하거나 puts()로 출력한다.
puts(ppstrList[0]);
puts(ppstrList[1]);
puts(ppstrList[2]);
// char***를 두 번 간접지정하면 char*이다.
puts(*pppstrList[0]);
puts(*(*(pppstrList + 0) + 1));
return 0;
}
위 예제는 포인터의 배열과 다중 포인터가 뒤섞인 형태의 프로그램이다. 예제에서 ppstrList는 모두 astrList로 대체될 수 있다. ppstrList는 변수이고 astrList는 그 안에 저장된 정보이기 때문이다.
어차피 간접지정 연산([])의 대상은 변수 그 자체가 아니라 그 안에 저장된 정보이므로 *ppstrList나 *strList는 서로 같다. 또한 *pppstrList[0]에서 가장 먼저 수행되는 것은 간접지정연산이 아니라 배열연산이다. 이것을 풀어서 쓰면 **(pppstrList + 0)이 된다. pppstrList + 0 연산 결과 자료형은 char*** 이므로 여기에 두 번 간접지정한 결과는 char*가 되므로 puts()함수의 인수로 적절하다.
다차원 배열에 대한 포인터 배열은 여러 요소가 모여 한 덩어리를 이룬 것이다. 만약 배열을 이룬 요소가 다시 배열이라면, 이를 2차원 배열이라고 부른다.
2차원 배열이라는 것은 정확히 말하자면 요소가 배열인 배열이다. 배열의 식별자인 주소를 저장할 수 있는 포인터 변수는 '배열 요소의 자료형에 대한 포인터'이다.
char[3][16] 배열은 char[16]이 요소이고, 개수가 3개인 배열을 뜻한다. 이때 char[3][16]배열의 식별자인 주소를 저장할 수 있는 포인터 변수는 char[16]* 이라 할 수 있다.
하지만 이대로 표기하는 것은 문법 오류이다. 따라서 한 단계 더 처리하여 올바르게 다차원 배열에 대한 포인터 변수를 선언해야 한다.
예제에서 char (*pstrList)[12] = astrList;가 핵심 구문이다. 이 구문은 배열의 요소가 char형인 2행 16열로 선언된 astrList를 초깃값으로 선언 한, 2차원 배열에 대한 포인터 선언 및 정의를 의미한다.
2차원 배열은 배열에 대한 배열이고, 배열의 요소 자료형이 char[12]이므로 char[12]* 라고 선언하면 직관적이겠지만 이는 문법적으로 허용되지 않는다.
문법적으로 바른 표현이 되려면 오른쪽 끝에 있는 *를 char와 [12] 사이로 옮겨야 하는데, 반드시 이를 괄호로 묶어주어야 한다. 따라서 char(*)[12] 라고 표현해야 옳다.
또한 포인터 변수의 이름은 7번 행에서 본 것처럼 *의 오른쪽에 기술한다. 이때 2차원 배열의 이름(주소)를 char** 포인터에 담으려 한다면 잘못된 것이다. "배열의 요소 자료형에 대한 포인터에 담는다"가 맞기 때문이다.
변수와 메모리 변수의 본질은 메모리이다. 개념적으로는 주기억장치 메모리를 의미하는데, 우리가 사용할 수 있는 메모리는 스택, 힙, 텍스트, 데이터 영역의 메모리로 나뉜다.
변수를 선언하는 것은 함수 내부에 속한 지역 변수를 의미하며, 지역 변수는 기본적으로 네 종류의 메모리 중에서도 스택(stack) 영역에 속한다. 스택 구조의 메모리는 관리가 자동으로 이뤄지므로 스택을 사용하는 변수를 자동변수라고 부른다.
변수를 선언할 때는 어떤 메모리를 사용할지 명시해야 하는데(기억부류 지정자 자료형 변수이름 = 초깃값;), 아무런 언급이 없는 지역변수의 경우 컴파일러가 스스로 자동변수로 처리해준다(auto). 따라서 지역변수를 선언하면서 할당되는 메모리의 종류에 대해서는 별도로 명시할 필요가 없다. ※ C++ 11부터 auto의 의미가 달라졌으므로 이는 C언어에서만 해당되는 사항임을 유의하자.
메모리의 종류는 'storage-class'로 표기하는데, 우리말로 '기억부류' 혹은 '기억류'라고 한다. 변수를 선언할 때 자료형 앞에 기억부류를 명시하는 예약어를 기억부류 지정자(storage-class specifer)라고 한다.
c언어에서 이러한 기억부류 지정자로 기술 할 수 있는 예약어는 extern, auto, static, register 등이 있는데 각각 외부, 자동, 정적, 레지스터라고 부른다.
여기서 레지스터란 일반 메모리가 아닌 CPU가 가진 메모리로 입출력 속도가 CPU와 같으므로 컴퓨터에서 가장 빠른 메모리이다.
전역 변수 혹은 정적변수가 사용하는 데이터 영역 메모리는 프로그램이 시작될 때 확보되어 종료시까지 유지된다. 따라서 스택 메모리 영역을 사용하는 지역변수의 경우처럼 스코프가 닫힌다 해도 메모리가 사라지지 않는다.
정적변수 static 정적변수는 데이터 영역에 저장되는 변수로, 함수의 호출 및 반환과 아무런 관련이 없어 사실상 전역 변수처럼 작동한다. 다만 정적변수와 전역변수의 차이는 정적 변수의 경우 그 접근성이 자신이 선언된 함수 내부로 제한된다는 것이다.
#include <stdio.h>
int TestFunc(void)
{
// 접근성은 TestFunc() 내부로 제한된 지역변수이지만
// 기억 부류는 스택이 아니라 데이터 영역인 '정적' 변수 선언 및 정의
// 정의는 이 함수가 여러 번 호출되더라도 단 한번만 적용된다.
static int nData = 10;
// nData의 값이 변경됐다.
// 정적변수이므로 이 변경된 값은 함수가 반환되더라도 유지된다.
++nData;
return nData;
}
int main(int argc, char* argv[])
{
// TestFunc() 함수를 호출할 때마다 다른 Data 값을 반환받는다.
printf("%d\n", TestFunc());
printf("%d\n", TestFunc());
printf("%d\n", TestFunc());
}
정적 변수는 선언시 반드시 static 예약어를 자료형 앞에 기술해야 한다. 또한 정적 변수는 처음 선언될 때 딱 한 번만 초기화된다는 특징이 있다. 따라서 위 예제에서 총 3번 함수를 호출하고 있지만 첫번째로 선언되었을 때 초기화된 static 변수 값은 다시 초기화되지 않으므로 두번째로 함수가 호출될 때부터는 초기화 부분은 건너뛰고 값을 더하는 로직만 실행된다.
또한 함수가 반환되어도 메모리가 사라지지 않으므로 이 정적 변수는 전역변수처럼 그대로 존재하게 된다. 따라서 예제의 출력 결과는 11, 12, 13이 된다.
정적 변수는 전역 변수에 비해 독립된 두 함수를 논리적으로 하나로 연결하여 불필요한 의존성을 만들지 않는다. 그러나 기술적 면에서는 전역변수와 정적변수 모두 '동시성(concurrency)'을 지원하기 어렵다는 단점이 있다. 동시성은 병렬처리와 직결되고 이것은 궁극적으로 성능과 직결되므로 정적변수를 사용하는 데는 신중해야 한다.
레지스터 변수 register 레지스터 변수는 CPU의 레지스터를 사용하기 위한 것인데, 이는 과거 주기억장치의 속도가 비교적 느리던 시절에 사용되던 변수이다. 현재는 컴파일러 기술이 매우 발전하였으므로 임베디드 운영체제를 위한 프로그램을 제작하는 경우가 아니라면 레지스터 변수를 다룰 일은 거의 없다.
하지만 한 가지 주의해야 할 특징을 짚고 넘어가자면 레지스터 변수는 CPU의 일부이기 때문에 별도로 주소가 없다는 점이다. 따라서 일반 메모리와 달리 주소가 아닌 고유명사로 식별된다.
따라서 레지스터 변수는 일반 변수처럼 주소 연산을 할 수 없다. 이 특징 외에 다른 사용법은 일반 자동변수와 동일하다.
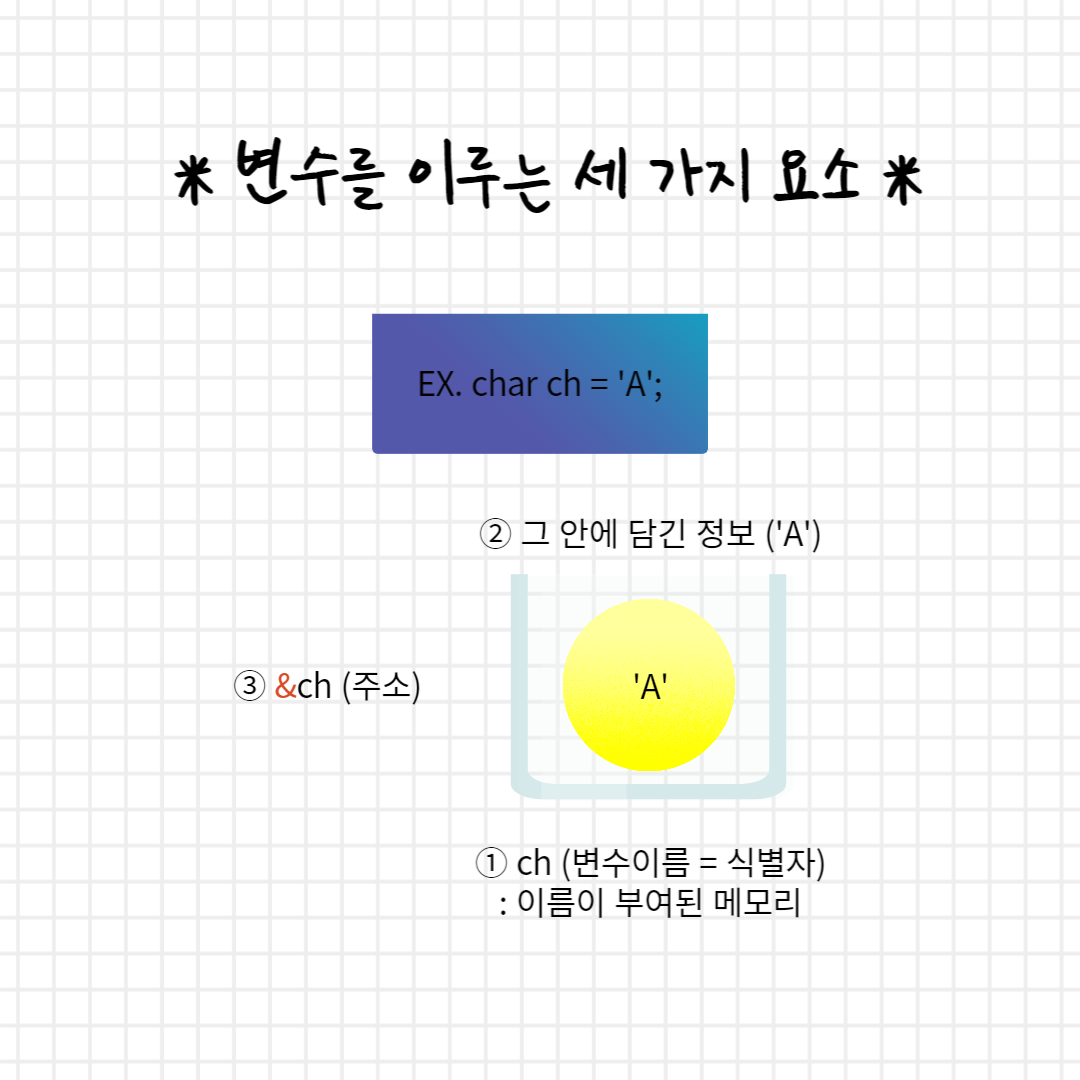
컴퓨터와 메모리 변수의 본질은 메모리이며, 모든 메모리는 자신의 위치를 식별하기 위한 근거로 고유번호를 가지는데, 이 번호를 메모리의 주소라고 한다. 이러한 메모리 주소는 보통 16진수로 표기한다.
변수의 선언 및 정의는 메모리 확보를 의미하며 선언시 부여한 이름으로 확보한 메모리를 식별한다.
변수를 이루는 세가지 요소 1. 이름이 부여된 메모리 2. 그 안에 담긴 정보 3. 메모리의 주소
단항 연산자인 주소 번지 연산자(=주소 연산자, &)를 사용하면 선택한 메모리의 주소를 가져올 수 있다. 이를 %p 형식(주소 형식)으로 출력하면 16진수로 구성된 주소가 출력된다.
포인터 변수의 선언과 정의 포인터 변수는 메모리의 주소를 저장하기 위한 전용 변수이다. 모든 바이트 단위 메모리에는 고유번호(주소)가 붙어있다. 또한 이는 위치정보라고 생각할 수 있다.
프로그래머가 메모리를 직접 다루고 싶을 때는 그 주소를 컴파일러에게 물어봐야 한다. 이때 주소 연산자(&)를 사용하면 컴파일러는 해당 메모리의 주소를 알려준다.
'&nData'라는 연산은 "이름이 nData인 메모리의 실제 주소는?"이라는 의미이다.
주소 연산자와 반대되는 개념의 연산자로 '간접지정 연산자(*)'가 존재한다. 여기서 지정이라는 말은 임의 대상 메모리에 대한 길이와 해석방법, 즉 자료형을 지정한다는 뜻이다. 자료형이란 일정 길이(혹은 크기)의 메모리에 저장된 정보를 해석하는 방법이라고 할 수 있다.
그렇기 때문에 만약 메모리를 int형으로 지정한다고 한다면, 이것은 총 네 바이트의 메모리를 한 세트로 보고 그것을 int형 변수로 취급하겠다는 말이 된다.
메모리의 직접지정과 간접지정
어떤 메모리를 이렇게 int형으로 지정하는 방법은 '직접지정'과 '간접지정'이 있다.
여기서 직접지정이란 특정 주소에서 네 바이트 메모리를 int형 변수로 보겠다고 확정하는 방법이다. 즉 개념적으로 직접지정한 주소를 확정하여 식별하는 방식인 것이다. 흔히 변수를 선언 및 정의하여 메모리를 사용하는 방식이 바로 이 직접지정 방식을 말한다.
반면 간접지정은 변경될 수 있는 임의의 기준주소로 상대적인 위치(주소)를 식별하는 방법을 말한다. 어떤 특정 기준을 근거로 상대인 메모리의 위치를 설명하는 방법으로, 우리가 어떤 건물을 지칭할 때 건물 주소를 직접 말할 수도 있지만 "OO 편의점 옆 건물" 과 같이 특정 기준을 가지고 지칭 할 수 있는 것과 같다.
#include <stdio.h>
int main(void)
{
// int 형식 변수 선언 및 정의
int x = 10;
// 변수 x를 가리키는 int 형식에 대한 포인터 변수 선언 및 정의
int* pnData = &x;
printf("x : %d\n", x);
// pnData 포인터 변수가 가리키는 대상 메모리를 int형 변수로 간접 지정하고 20을 대입한다.
// 현재 가리키는 대상 메모리는 변수 x의 메모리이므로 x의 값이 20이 된다.
*pnData = 20;
printf("x : %d\n", x);
return 0;
}
&pnData : 식별자가 pnData인 대상에 대해 단항 주소 연산을 수행함. -> 결과적으로 이름이 pnData인 메모리의 주소가 됨.
*pnData : 포인터 변수 pnData에 저장된 주소를 가진 메모리를 int형 변수로 취급함.
포인터의 핵심 동작?
1. 주소를 가리킬 수 있다.
2. 그 주소를 받는 변수를 선언할 수 있다.
3. 그 주소 변수를 이용해서 내가 알고 있는 주소로 가서 거기에 저장된 값을 직접 수정할 수 있다.
// 포인터 변수
// 주소를 저장하는 변수 -> (*)을 붙이지 않으면 일반 변수가 된다. (*)를 붙이면 포인터 변수가 된다.
// nullptr == 0, 해당 포인터가 아무것도 가리키지 않는다는 뜻으로 사용
int* pInt = nullptr;
// 위의 포인터 변수는 int 포인터를 가리키는 변수라는 뜻이다.
위의 내용을 전제로 아래의 내용이 성립한다.
// 포인트 변수 선언
int i = 100;
int* pInt = &i; // i라는 변수의 주소값을 가져온다. (&) -> 주소값을 의미
주소란? 메모리 공간 안에 데이터들이 0,1, 0, 1... 식으로 비트파이트 단위로 있는데, 이때 이 데이터들의 위치를 지칭한다. 예시로, 어디 공간에 뭘 넣으라고 했을 때 명령을 수행하기 위해서는 그 공간의 위치를 알 수 있어야 한다. 그 특정 메모리의 위치를 지칭하는 것이 주소다. 이러한 주소 개념을 C/C++ 문법에서 활용할 수 있다.
// 포인트 변수 선언
int i = 100;
int* pInt = &i; // i라는 변수의 주소값을 가져온다. (&) -> 주소값을 의미
// 1. 주소를 가리킬 수 있다.(&)
// 2. 그 주소를 저장하는 변수를 만들 수 있다 (*)
// 포인터 값 할당
(*pInt) = 100; // i라는 변수에 100이 할당된다.
// 3. 주소 변수를 이용해서 내가 알고 있는 주소로 가서 직접 내용을 수정한다.
포인터가 주소를 저장하는 방식은 정수 방식일까 실수 방식일까? 포인터형 변수가 내부의 데이터를 처리할 때 어떤 방식을 사용하는지 알기 위해서는 먼저 주소의 단위를 알아야 한다.
// 주소의 단위
100;
105;
100과 105 사이에 있는 5개 칸이 1개당 얼마의 메모리를 가질까? 그 주소 단위를 알아야 한다. 이때 주소의 단위는 바이트(Byte)이다. 이 1byte는 다시 8개의 bit로 쪼갤 수 있다.
- 그렇다면 더 세부적인 비트 단위까지 주소를 부여할 수 있을까?
아니다. 주소 단위 자체가 바이트이기 때문이다.
- 그럼 주소를 표현하는 방식은 무엇인가?
실수가 아닌 정수 타입이다. 따라서 100번과 105번 사이에 100.5번지 같은 실수는 존재할 수 없다. 이와 같은 이유 때문에 더더욱 비트단위로 주소를 보유할 수 없다. 만약 아래처럼 100번과 102번 주소가 있다고 가정하면 이 둘 사이에는 2byte의 여유 공간이 존재한다.
- 왜 포인터 변수를 선언할 때 자료형을 적어줘야할까? 포인터 변수가 가지고 있는 정보는 주소밖에 없기 때문에 그 주소를 찾아갔을 때 int가 있는지 char가 있는지 알 수 없다. 따라서 포인터 변수는 선언할 때 어떤 자료형의 포인터인지 알려주어야한다. 해당 주소에 가서 어디에 접근해야하는지 알려주기 위함이다. (자료형이 int라면 4Byte에 접근)
즉, 포인터 앞에 선언되는 자료형의 의미는 자기가 가리킬 데이터의 타입을 정해놓는 것이다. 그렇기 때문에 접근 시에 이 타입의 사이즈에 딱 맞춰서 접근할 수 있는 것이다.
하지만 여기서는 단순히 사이즈만 문제가 되는 것이 아니다. int변수는 정수형 표현방식이다. 그것까지도 포함되어 있다. 실수와 정수는 비트 단위에서 표현하는 방식 자체가 다르기 때문에 이를 구분하는 것은 매우 중요하다. 정수 표현 방식은 비트 수를 이진법 기준으로 하지만 실수는 가수, 지수 등으로 부동소수점을 사용하여 완전히 다르게 수를 표현한다.
예를 들어 다음과 같은 변수가 있다고 가정하자.
float f = 3.f;
위의 변수는 정수 3이 아닌 실수 3을 나타낸다. 만약 이것을 동일한 4byte 사이즈를 가진 int 포인터 변수에서 접근하도록 하면 어떻게 될까?
int i = 100;
float f = 3.f;
int* pInt = &f; // int 포인터에 실수 타입 변수 주소에 접근하도록 하면 어떻게 될까? 오류가 뜬다.
// 주소로 접근
(*pInt) = 100;
바로 컴파일러에서 오류를 표시한다. 서로 타입이 맞지 않기 때문에 문법차원에서 방어를 해주는 것이다.
하지만 아래 코드처럼 강제 캐스팅을 이용하면 억지로 f 주소값을 int 포인터 변수에 넣을 수 있다.
int* pInt = (int*)&f;
이 경우 오류는 뜨지 않는다. 결과적으로 실수값의 주소가 int 포인터 변수에 들어오게 된다.
이 변수는 애초에 int 주소 변수만 받겠다고 선언한 상태지만 강제 캐스팅로 인해 실체가 float가 된 것이다.
int i = 100;
float f = 3.f;
int* pInt = (int*)&f;
// 주소로 접근
i = *pInt;
이때 디버깅을 해보면 i에 엄청 큰 숫자가 들어가있음을 알 수 있다. int포인터는 주소를 받아서 갔을 때 그것을 int로 간주하겠다는 의미를 가지고 있는데 그곳에 int가 아닌 float 주소를 넣었기 때문이다.
앞서 말했듯, int인 정수 표현방식과 float의 실수 표현 방식은 다르다. float에는 실수표현방식으로 실수 3을 표현하기 위한 비트가 들어가있는데 그것을 int 정수 형식으로 해석해버리니 잘못된 숫자가 들어가게 되는 것이다.
정리하면 다음과 같다.
<포인터 변수 자료형 선언> 자료형 + * EX. int* (*)이 붙었으므로 이것은 포인터 변수가 된다. 이때 앞에 붙는 자료형의 의미는 바로 해당 포인터 변수에게 전달된 주소를 해석하는 단위이다
visual studio의 내부 단위는 솔루션 -> 프로젝트파일(프로그램의 실체, 여러 개가 있을 수 있음) -> 그 외 서포팅을 위한 외부 라이브러리 등이 있다.
또한 디버그, 릴리즈 모드가 나눠져있으며 솔루션 플랫폼이 32비트(x86)용, 64비트 용이 존재한다. 지금은 64비트를 사용하는 것이 대중적이지만 32비트 기반 운영체제에서도 사용 가능하도록 비주얼 스튜디오가 빌드 기능을 지원하고 있다.
대부분의 게임도 최저 사양으로 윈도우 64비트를 요구한다. 이는 게임의 사양이 높아졌기 때문이다. x86, x64는 OS의 데이터 처리 단위를 말한다. 그것이 작아지면 높은 사양의 게임을 실행할 때 메모리 문제가 발생한다. 따라서 32비트 운영체제에서는 PC 성능이 아무리 좋아도 높은 사양의 게임을 정상 실행할 수 없다. (신체의 스펙_하드웨어는 좋지만 머리_데이터 처리 단위가 따라주지않는 것 같이 하드웨어의 진짜 성능을 끌어내지 못한다.)
플랫폼이란 뭘까? 무언가가 실행되기 위한 기반이다.
EX. 구글 플레이 스토어(안드로이드 OS 환경에서 실행되는 프로그램을 판매, 안드로이드 OS자체가 기반이 되는 플랫폼이 된다.), Window도 일종의 플랫폼이다. 그리고 이러한 window안에서도 게임을 판매하는 unreal 스토어나, 스팀, 오리진 등이 있다. 이때 스팀에서 구매한 게임은 스팀에서만 실행할 수 있지 unreal 스토어에서는 실행할 수 없다. 이러한 개념이 플랫폼이다.